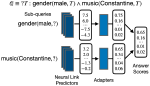
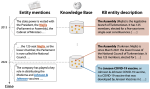
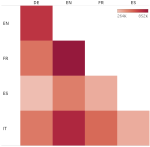
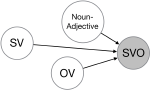
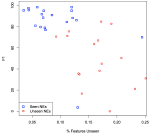
Information extraction is concerned with extracting information about entities, phrases and relations between them from text to populate knowledge bases, such as extracting “employee-at” relations. Within this context, we have worked on automatic knowledge base completion, knowledge base cleansing and detecting scientific keyphrases in text, as well as automatic completion of typological knowledge bases.
We are currently involved in one longer-term project related to this, namely a research project funded by the Swedish Research Council coordinated by Robert Östling. Its goals are to study structured multilinguality, i.e. the idea of using language representations and typological knowledge bases to guide which information to share between specific languages.