We are working on studying methods to automatically process scholarly data. This is to assist researchers in finding publications (e.g. by extracting content from papers automatically, which can be used to populate knowledge bases), writing better papers (e.g. by suggesting which sentences need citations, improving peer review), or tracking their impact (e.g. by tracking which papers are highly cited and how this relates to meta-data, such as venues or authors).
Scholarly Data Processing
Publications
Modeling Public Perceptions of Science in Media
Effectively engaging the public with science is vital for fostering trust and understanding in our scientific community. Yet, with an …

Understanding Fine-grained Distortions in Reports of Scientific Findings
Distorted science communication harms individuals and society as it can lead to unhealthy behavior change and decrease trust in …

Modeling Information Change in Science Communication with Semantically Matched Paraphrases
Whether the media faithfully communicate scientific information has long been a core issue to the science community. Automatically …

Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings
Learning scientific document representations can be substantially improved through contrastive learning objectives, where the challenge …

Generating Scientific Claims for Zero-Shot Scientific Fact Checking
Automated scientific fact checking is difficult due to the complexity of scientific language and a lack of significant amounts of …

Longitudinal Citation Prediction using Temporal Graph Neural Networks
Citation count prediction is the task of predicting the number of citations a paper has gained after a period of time. Prior work …
Semi-Supervised Exaggeration Detection of Health Science Press Releases
Public trust in science depends on honest and factual communication of scientific papers. However, recent studies have demonstrated a …
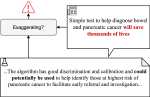
Determining the Credibility of Science Communication
Most work on scholarly document processing assumes that the information processed is trust-worthy and factually correct. However, this …
CiteWorth: Cite-Worthiness Detection for Improved Scientific Document Understanding
Scientific document understanding is challenging as the data is highly domain specific and diverse. However, datasets for tasks with …
Claim Check-Worthiness Detection as Positive Unlabelled Learning
A critical component of automatically combating misinformation is the detection of fact check-worthiness, i.e. determining if a piece …

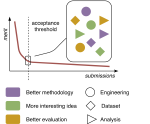
What Can We Do to Improve Peer Review in NLP?
Peer review is our best tool for judging the quality of conference submissions, but it is becoming increasingly spurious. We argue that …
Back to the Future -- Sequential Alignment of Text Representations
Language evolves over time in many ways relevant to natural language processing tasks. For example, recent occurrences of tokens …
A Supervised Approach to Extractive Summarisation of Scientific Papers
Automatic summarisation is a popular approach to reduce a document to its main arguments. Recent research in the area has focused on …

Multi-Task Learning of Keyphrase Boundary Classification
Keyphrase boundary classification (KBC) is the task of detecting keyphrases in scientific articles and labelling them with respect to …